The search engines have an enormous task—that of indexing the
world’s online content; well, more or less. The reality is that they try
hard to discover all of it, but they do not choose to include all of it in
their index. This can happen for a variety of reasons, such as the page
being inaccessible to the spider, being penalized, or not having enough
link juice to merit inclusion.When you launch a new site, or add new sections to an existing site,
or are dealing with a very large site, not every page will necessarily
make it into the index. To get a handle on this you will want to actively
track the indexing level of your site. If your site is not fully indexed,
it could be a sign of a problem (not enough links, poor site structure,
etc.).
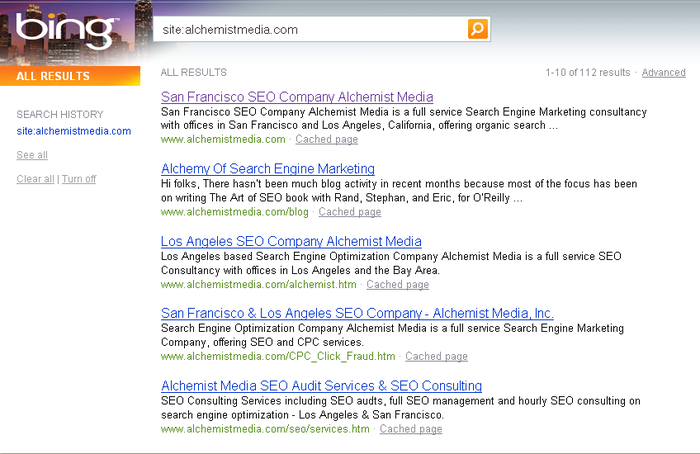
Getting basic indexation data from search engines is pretty easy.
All three major search engines support the same basic syntax for that,
which is site:yourdomain.com. Figure 1 shows a sample of the output from
Bing.
Keeping a log of the level of indexation over time can help you
understand how things are progressing. This can take the form of a simple
spreadsheet.
Related to indexation is the crawl rate of the site. Google provides
this data in Google Webmaster Central. Figure 2 shows a screen shot
representative of the crawl rate charts that are available (another chart,
not shown here, displays the average time spent downloading a page on your
site).
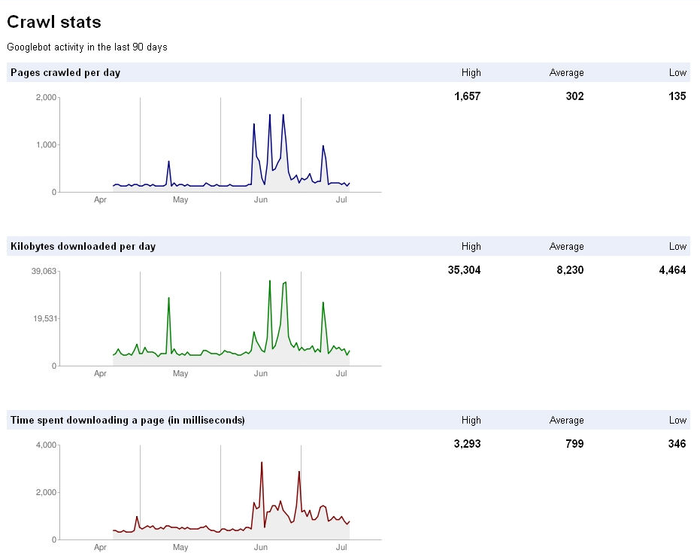
Short-term spikes are not a cause for concern, nor are periodic
drops in levels of crawling. What is important is the general trend. In
Figure 2, the crawl rate
seems to be drifting upward. This bodes well for both rankings and
indexation.
For the other search engines, the crawl-related data can then be
revealed using logfile analyzers , and then a similar
time line can be created and monitored.